






AIエージェントの作り方|知識と経験を”AIが読めるデータ”にする方法
- AIエージェント営業用プレゼン資料|あなたの経験とノウハウを仕組みにするという選択
- AIエージェント教育用プレゼン資料|AIってなにができるの?から始める人のために
- AIエージェント活用事例集|AIエージェント、こんなところで使えます
- [icon name="download" style="solid" class="" unprefixed_class=""] AIエージェント導入チェックシート(AI Agent Introduction Checklist)
AIエージェントを構築するうえで重要なステップが、「AIに読める形に変換する」処理です。ここでは、構造化された知識(ナリッジ)を、AIが意味で検索・応答できるように変換する流れを解説します。技術者用の情報です。
1. 入力データの構造(チャンク)
あらかじめ、以下のような形で「意味のかたまり=チャンク」に整理されている必要があります。
0001 JOIN
0002 {
0003 "title": "犬の無駄吠えをやめさせたい",
0004 "section": "玄関チャイムに反応して吠える",
0005 "content": "チャイム音に条件反射で吠えることが多い。まずはチャイム音に慣れさせる訓練を行う..."
0006 }
2. エンベディング=ベクトル化
AIは、文字列のままでは検索ができません。そこで、テキストを「意味」で検索できるようにするために、多次元の数値データに変換します。この処理を「エンベディング(ベクトル化)」と呼びます。
-
エンベディングとは?
テキスト(自然文)を数百個の数字の配列(ベクトル)に変換する処理です。 -
ベクトルとは?
変換された後の「数値のかたまり」のこと。文章同士の意味の近さを距離で判断できます。 -
ベクトル化とは?
実務上は「エンベディングすること」と同じ意味で使われます。
3. エンジニアが行う処理
エンベディングは、OpenAIやHuggingFaceなどの外部APIを使って、テキストを送るだけでベクトルが返ってくる仕組みになっています。
0001 pyson
0002 from openai import OpenAIEmbeddings
0003
0004 embedding = OpenAIEmbeddings(model="text-embedding-ada-002")
0005 vector = embedding.embed_query("チャイム音に条件反射で吠えることが多い...")
0006
4. ナリッジデータベースへの保存形式(例)
ベクトルは、チャンクと一緒に以下のように保存されます。
0001 JOIN
0002 {
0003 "id": "a1b2c3",
0004 "title": "犬の無駄吠えをやめさせたい",
0005 "section": "玄関チャイムに反応して吠える",
0006 "content": "チャイム音に条件反射で吠えることが多い...",
0007 "vector": [0.021, -0.554, 0.994, ...]
0008 }
これが、AIが参照する「ナリッジベース(知識データベース)」になります。
5. 補足:保存先の注意
-
通常は、Pinecone、Chroma、Weaviateなどのベクトル検索専用データベースに保存します。
-
WordPressにベクトルを直接保存するのは推奨されません(検索が非効率・非現実的なため)。
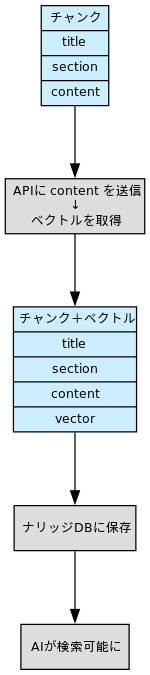
チャンク → ベクトル → ナリッジベースの全体像
-
チャンクを作る
title・section・content で構成された、意味のかたまり。 -
APIに投げるのは“content部分(=自然文)”
→ OpenAIなどのエンベディングAPIに送信(トークン単位で課金) -
返ってくるのは“ベクトル(数値の配列)”
例:[0.023, -0.994, 0.812, ...]← AIが意味ベースで検索できる形 -
そのベクトルを、元のチャンクに“突っ込んで”1つのオブジェクトにする
→ JSONなどの形式でまとめる -
それをナリッジデータベースに保存する
→ Pinecone, Chroma, Weaviate, FAISSなどに書き込む
まとめ
-
チャンクは「title・section・content」で構成された情報のかたまり。
-
それをエンベディング処理によってベクトル化することで、AIが意味で検索・応答できるようになります。
-
エンベディング処理はAPIで完結。エンジニアの役割は、データ構造の整備とAPI連携、DB登録の設計です。
- AIエージェント営業用プレゼン資料|あなたの経験とノウハウを仕組みにするという選択
- AIエージェント教育用プレゼン資料|AIってなにができるの?から始める人のために
- AIエージェント活用事例集|AIエージェント、こんなところで使えます
- [icon name="download" style="solid" class="" unprefixed_class=""] AIエージェント導入チェックシート(AI Agent Introduction Checklist)





